Leading Tamarind Bio's Series A - The ML Operating System for Life Science

The Models are Here
For much of the past decade, even during the AI boom across other sectors, the applicability of machine learning to problems in life science was a greatly debated topic in the field. Certainly, the previous waves of computational advancements that have come before (molecular docking in the 80s, computational chemistry in the 90s, and bioinformatics in the 2000s) did not usher in a panacea of productivity in drug discovery. The few technological maximalists on one side were drowned out by skeptics who argued that biology was too complex for simulation tools and these skeptics were largely right. The models developed in the 2010’s were often narrow, brittle, and fell short of predictive power to have utility as a production tool for the industry.
AlphaFold's near-complete solution to the protein folding problem, recognized with a Nobel Prize in 2024, was a watershed moment for the development of machine learning in life science and the mark of a new era of computing. In the few short years after AlphaFold2, a steady stream of benchmark-breaking models has followed: ESMFold, Chai, ProGen, RoseTTAFold, DiffDock, Boltz, ProteinMPNN, RFDiffusion, and hundreds more, each advancing the state of the art for protein design, binding affinity prediction, small molecule generation, and molecular dynamics. New models are released with record-setting capabilities on a near monthly cadence.
Mass adoption by BioPharma and commercial developments have followed. Dimension portfolio company Chai announced a sweeping eight-figure deal with Lilly earlier this year. GSK committed $50M to Noetik to license its cancer foundation models — what Noetik's CEO Ron Alfa called "a new paradigm in biotech," marking the shift from one-off research collaborations to ML model and data licensing. The vast majority of top pharma companies have AI leads and CIOs that are focused on speeding up the adoption of this new technology. VC funding for AI drug development surpassed $2.7 billion through the first three quarters of 2025 alone.
The question is no longer whether ML models work across various problem domains in life sciences. The question is how far can they go, and how can this fast-moving technology manage to be enterprise-grade and permeate into this large sector.
Going Beyond Models
As the industry enters into a period of increasing ML adoption, companies of all types are discovering that operating these tools at scale is genuinely hard. The model landscape is fragmented and life science models are rarely used as standalone tools. There are a number of upstream and downstream dependencies to help these models come to life into full-featured workflows. A given drug discovery campaign might call on AlphaFold for structure prediction, ProteinMPNN for sequence design, a proprietary antibody model trained internally, and a third-party small molecule tool — none of which talk to each other by default. Each model runs on different infrastructure, requires different inputs, and returns outputs in different formats. Stitching them into a coherent workflow represents significant engineering effort.
There is also the infrastructure problem. Bench scientists are not ML engineers. But most ML tooling today is built for the technical user, requiring command-line access, cloud credentials, and substantial hand-holding to produce a result. The models need to be hosted, spun up at runtime, scaled horizontally to handle large batch jobs, and governed carefully to preserve IP and data security. When a computational tool demands that a scientist context-switch into a DevOps task to get something done, that tool is actually creating a new bottleneck instead of accelerating scientific research.
The Tamarind Platform
Tamarind Bio was founded to solve exactly this problem, built by founders who understood it from first-hand experience. Deniz Kavi, Tamarind's CEO, was an research student at Stanford running ML models for his labmates. Researchers would email him asking for an AlphaFold run. He'd execute it, email the results back, and move on to the next request. As the requests piled up, it became abundantly clear that an entire lab's applied AI capacity should not pass through one person's inbox. So Deniz and co-founder Sherry Liu built a self-serve solution. They posted about it online and six hundred researchers from around the world signed up within a month.
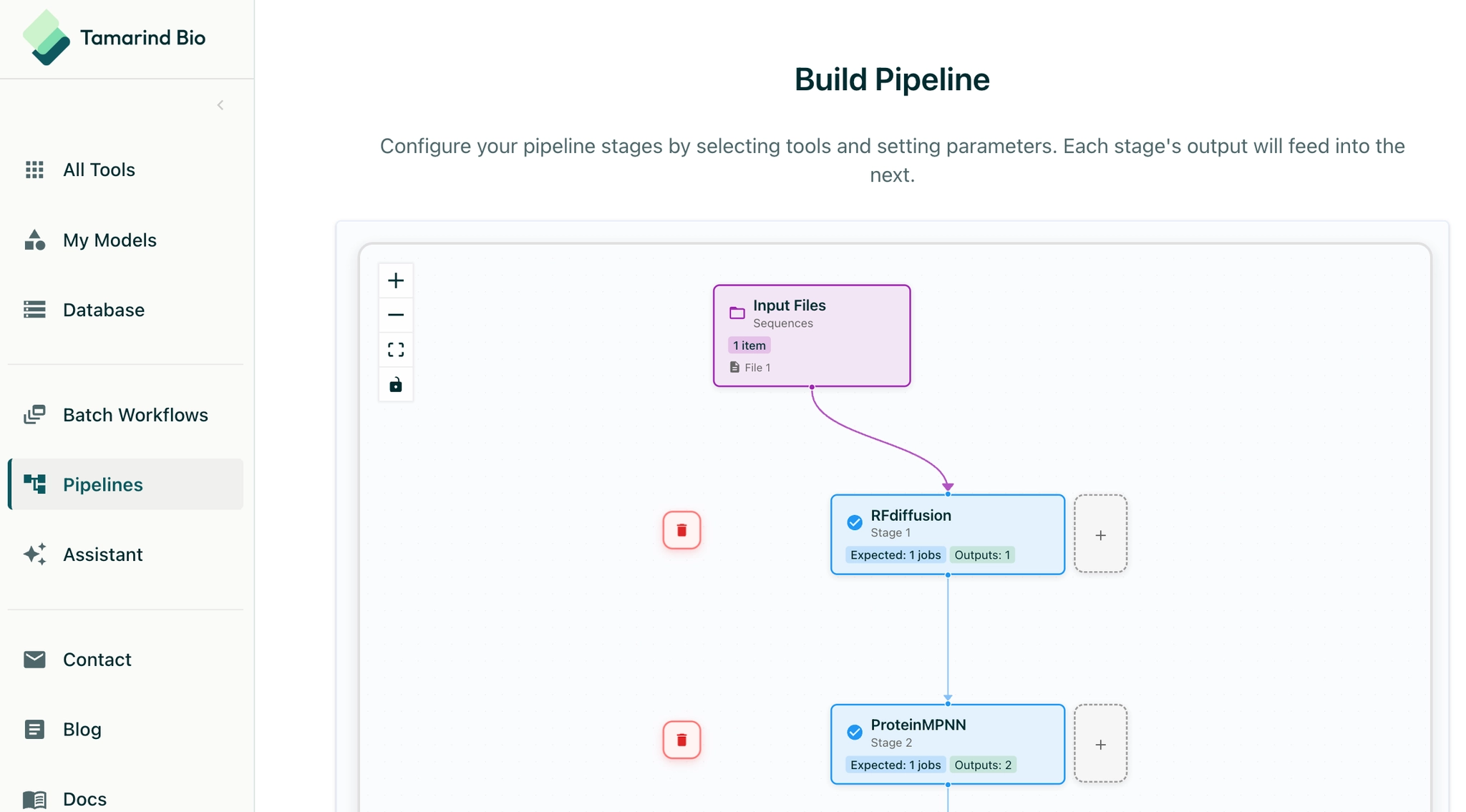
What started out as an open source model launchpad has grown into a full-featured inference cloud and operating system for ML in the life sciences. The platform abstracts away infrastructure overhead: hosting, compute provisioning, runtime orchestration, security, and data residency. The platform also offers a robust application layer of software tools to help users manage these ML runs. Scientists interact with a no-code interface that lets them stitch together open-source and proprietary models into multi-stage workflows — submitting their inputs, setting parameters, receiving results. Customers can now also use Tamarind to onboard and run proprietary models trained on their own data, build multi-model pipelines, create internal scientific apps, and manage entire computational workflows end-to-end. These workflows and underlying models maintain state, can be shared across an organization, and can be versioned for reproducibility.
Tamarind helps users turn models turn into workflows, and workflows into scientific results with a central operating system for ML.
Investing in Tamarind
We were already aware of some of the issues with ML adoption problem from friends in the industry when we first met Tamarind, and were struck by how well the product fit into this problem. The company’s commercial progress since YC was indicative that the industry was finding their product organically and resonating with the solution that Tamarind created. After spending more time with Deniz and Sherry, we were also impressed with their obsession with user experiences and the quiet intensity that they demonstrated in the early phase of the company build.
Since we partnered earlier last year, Tamarind has grown revenue by 7x and has continued to expand software capabilities against an aggressive product roadmap. Most recently, the company signed a mid-seven-figure contract with a top-5 global pharma partner to power ML hosting. It continues to operate with zero dedicated sales and marketing spend.
The company has reached an inflection point with 8 of the top 20 pharmas as active users along with dozens of biotechs. As the industry continues to adopt ML tooling, Tamarind is increasingly embedded as a workflow orchestrator along the way. As Tamarind becomes the system of record for a company's computational workflows — the place where protocols live, models are trained, pipelines are shared, and results are archived — the surface area of the product will only continue to expand.
The Steady March
Twenty years ago, sequencing a single human genome took thirteen years and cost $2.7 billion. Today it takes hours and costs hundreds of dollars. Computational tools and advances in molecular approaches have the potential to leave a similar impact to the broader drug discovery process. The life science industry is still in the early innings of adoption of this new class of tools.
Tamarind's bet is that those tools should be accessible to every scientist, not just the ones with ML backgrounds and cloud credentials. That the infrastructure should be invisible. That the value should flow directly to the science. We believe that the steady march of the life science sector towards compute has already begun, is undeniable, and that much of this march goes through Tamarind.










